Inside LMCache: Anatomy of a KV-Cache Tiering Layer for vLLM
From a single vllm serve connector hook down to CPU, disk, and GPUDirect Storage backends — how a production KV cache reuses, tiers, and persists attention state.
In a previous post, "Inside vLLM: Anatomy of a High-Throughput LLM Inference System", Aleksa walked through a modern high-throughput inference engine from paged attention all the way to multi-node serving. Near the end, in the section on disaggregated prefill/decode, he hit a deliberate gap. vLLM ships a Connector abstraction for moving KV cache in and out of an engine instance, and he illustrated the mechanics with the toy SharedStorageConnector. He then noted:
I've also experimented with LMCache, the fastest production-ready connector ... but much of its complexity lives in an external repo, so
SharedStorageConnectoris a better choice for explanation.
This post fills that gap. LMCache is what you plug in when the local file directory needs to become a real, tiered, evicting, possibly-remote KV cache. We'll first recap the vLLM pieces LMCache plugs into, then start from one running example. After that, the post follows a single sequence diagram — twelve numbered steps, from the scheduler's first question to the final store — and walks it top to bottom, one step per section. We finish with a tour of the storage backends (CPU, disk, GDS) that make up the cold tiers.
A two-minute recap of vLLM
If you've just read "Inside vLLM", skip ahead to the running example. Otherwise, here is the compressed mental model — just the pieces LMCache plugs into.
In essence, vLLM does 3 things: request scheduling, KV-cache memory management, and model forwarding. Each step it decides which requests (and how many of their tokens) to run under the current memory/token budget, allocates and tracks the paged KV-cache blocks they need, and then flattens all the scheduled work into a single batched forward pass — rather than running one forward per request. That scheduler-driven batching (continuous batching) is what keeps the GPU saturated and gives vLLM its throughput.
Now the key concepts, one by one.
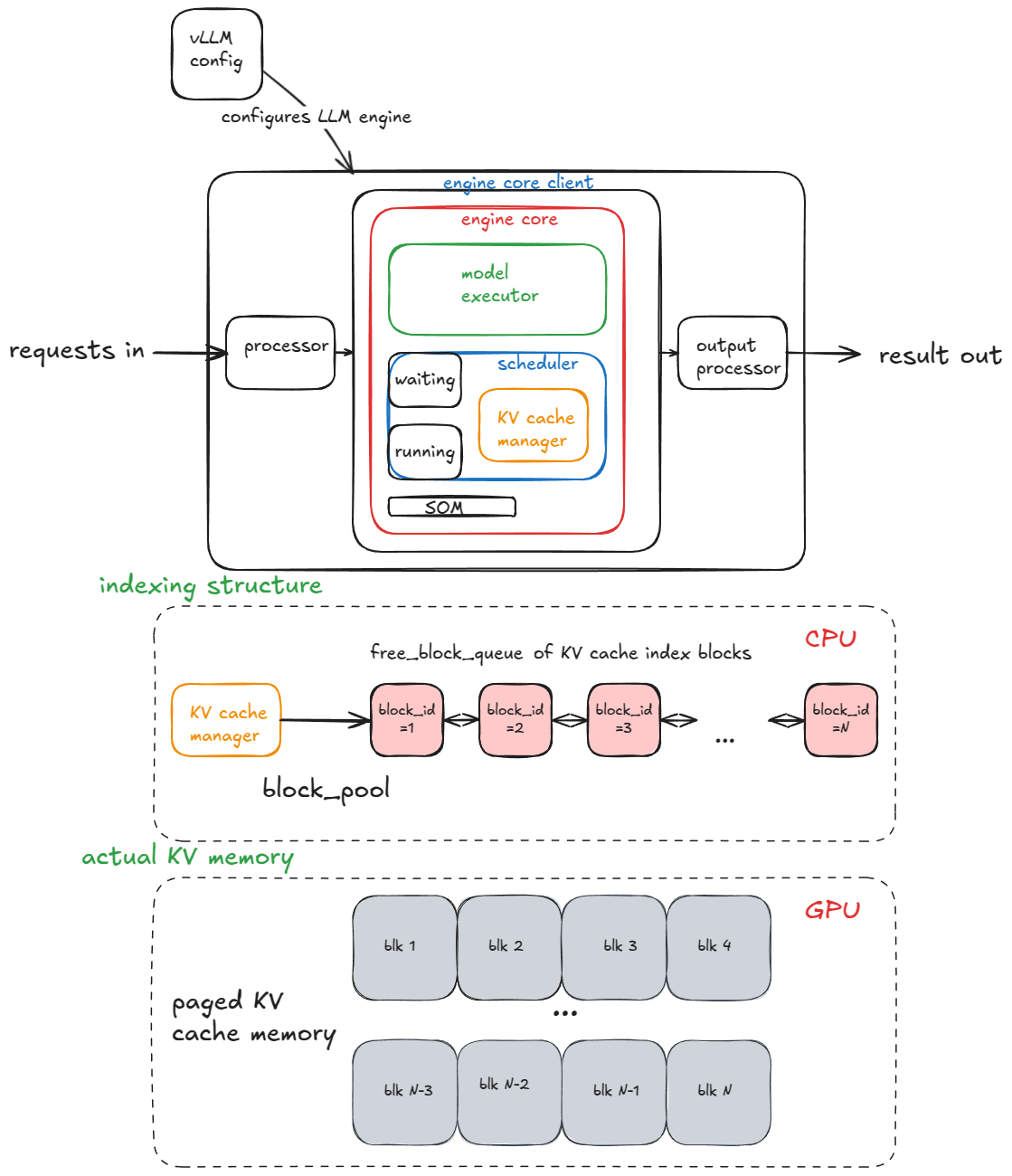
Engine = scheduler + worker. The engine is the most fundamental part of vLLM, and it consists of two halves:
 (figure: Aleksa Gordić, "Inside vLLM")
(figure: Aleksa Gordić, "Inside vLLM")
- The scheduler's most important component is the KV cache manager, the heart of paged attention. Internally it owns a
BlockPoolthat maintains afree_block_queue— a pool of blocks, where a block is the basic unit of KV-cache allocation/indexing (a fixed span of token slots, default 16 tokens). Crucially, these blocks are logical bookkeeping handles (KVCacheBlock), not the physical memory itself — that's the figure's middle band, living on the CPU. Each step, requests sit in the scheduler's waiting/running queues; when a request is scheduled,allocate_slotspops free blocks from the queue and assigns them to it. The blocks are whatever happened to be free, so a request's KV ends up scattered across the buffer, tracked by a per-request block table (e.g.[5, 2]). Keep that scattering in mind — we'll fight it repeatedly. - The worker's most important component is the
model_runner(GPUModelRunner), in charge of the forward pass. It also owns the physical KV-cache tensors (the figure's bottom band): at startup it allocates the raw VRAM buffer, reshapes it to[num_blocks, block_size, num_kv_heads, head_size]— one tensor per layer — and binds it into the attention layers. After that, the block indices the scheduler hands out map cleanly onto real memory.
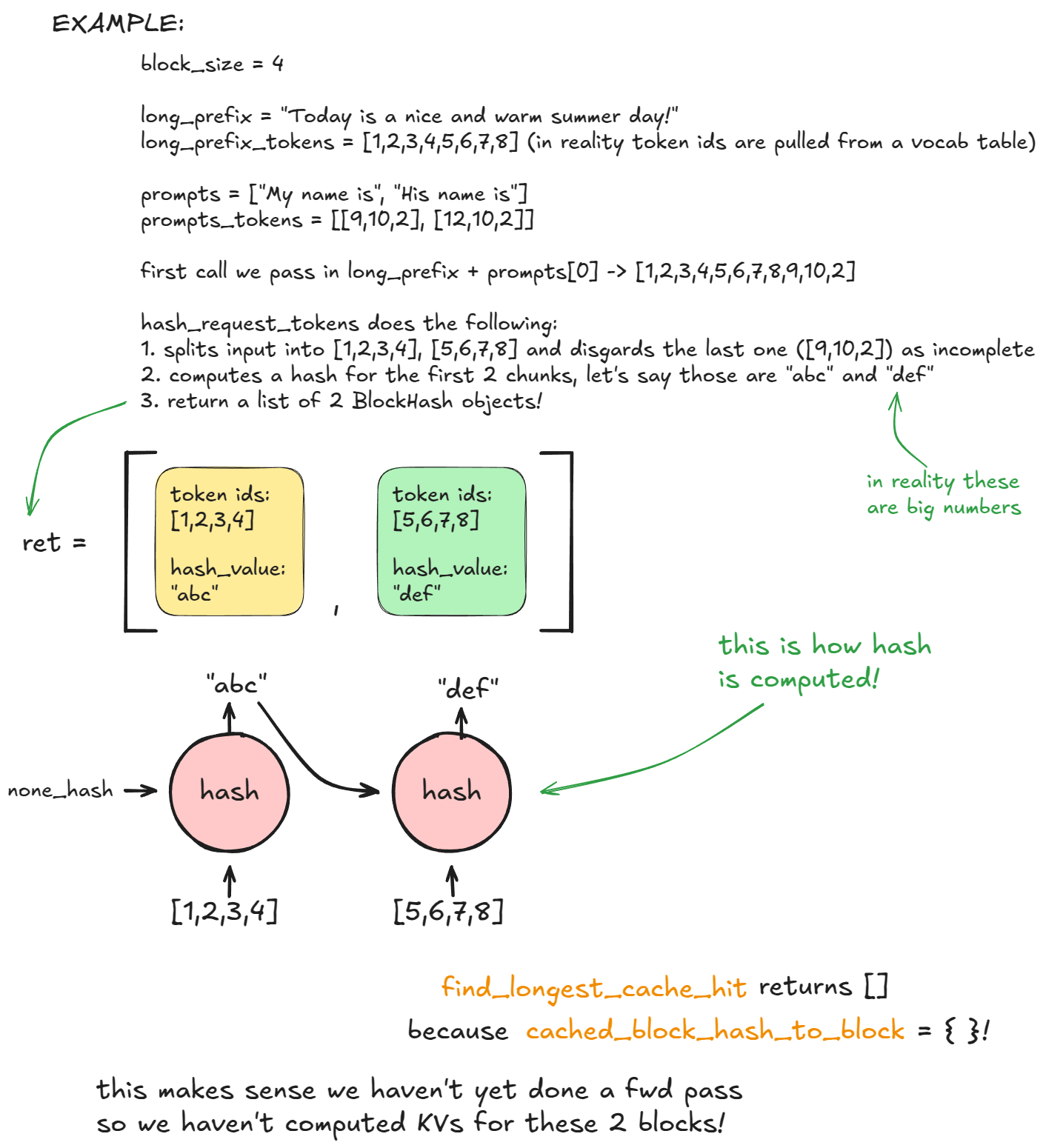
Prefix caching. When two requests share a leading span of tokens, vLLM hashes each 16-token block — each block's hash folding in the previous block's hash — and, on a hit, reuses the already-computed KV instead of recomputing it:
 (figure: Aleksa Gordić, "Inside vLLM")
(figure: Aleksa Gordić, "Inside vLLM")
This is the single most important idea for LMCache, so note its two properties: the chained hash means a hit on block N guarantees the whole prefix up to N matched (lookup = walk left to right, stop at first miss), and the key is content, not request identity — which is why one request can reuse blocks another request computed. But in vanilla vLLM the reuse stops at the edge of one engine's own GPU memory, and cached blocks get reclaimed the moment that memory is under pressure.
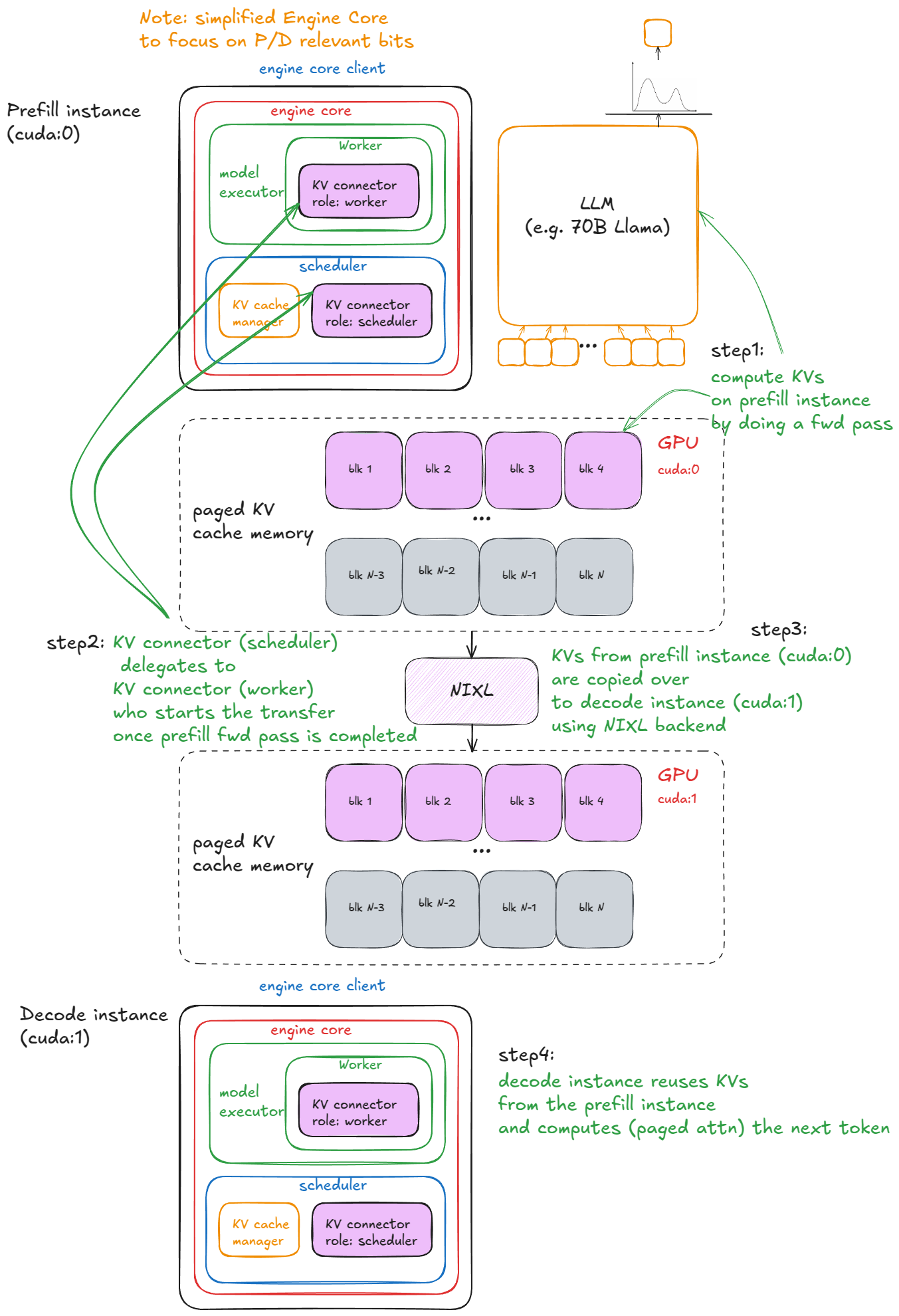
The connector & disaggregated P/D. To move KV across engine instances (e.g. a prefill pool writing KV that a separate decode pool reads), vLLM exposes a Connector interface: hooks where the scheduler can look up externally cached tokens, and the worker can load them in before the forward pass and save new KV out after.
 (figure: Aleksa Gordić, "Inside vLLM")
(figure: Aleksa Gordić, "Inside vLLM")
One detail in this figure to file away: inside each engine the connector appears twice — once as role: scheduler, once as role: worker. We'll see why at steps ⑤–⑥. The reference implementation, SharedStorageConnector, uses a local directory as its "external server."
Two limits of that picture are exactly what LMCache exists to remove: prefix reuse is confined to a single engine's memory, and the only built-in external store is a flat directory with no tiering, no eviction policy, and no path to CPU DRAM, disk, or NVMe. LMCache slots into the very same connector hooks, and replaces that flat directory with a real memory hierarchy.
Where vLLM's story is about KV cache inside GPUs (paged attention, the free_block_queue, block tables), LMCache's story begins the moment a KV chunk needs to outlive the GPU block that holds it — survive eviction, be shared with another request, spill to disk, or travel across the network. Three abstractions carry that story, and they recur in every section:
- The connector boundary — the handful of places where KV crosses between vLLM's paged buffer and LMCache.
- The chunk and its
CacheEngineKey— the unit of reuse, the analogue of vLLM's per-block hash but at coarser (default 256-token) granularity. - Who owns the memory a KV chunk lands in — the axis that distinguishes every storage backend, and the difference between an allocator backend and a plain storage backend.
Let's start with the running example.
The running example
Throughout this post we'll serve Llama-3.1-8B with vLLM and attach LMCache as the KV connector. Rather than the literal disaggregated-P/D setup from "Inside vLLM" (which needs two GPUs and two processes), we'll demonstrate the same idea — store KV in one phase, reuse it in the next — with one GPU and one process in two phases:
- Phase A ("store") — a first pass over the prompts. LMCache misses, vLLM computes the KV, and LMCache stores the prefix chunks.
- Phase B ("reuse") — the identical prompts again. LMCache hits, the prefix KV is loaded back into vLLM's paged buffer, and prefill recompute is skipped.
Here is the whole thing (the full script is lmcache_example.py):
from vllm import LLM, SamplingParams
from vllm.config import KVTransferConfig
# A long shared prefix so at least one full 256-token chunk is stored & reused.
LONG_PREFIX = "<a few hundred tokens of shared context>"
prompts = [
LONG_PREFIX + "Hello, my name is",
LONG_PREFIX + "The president of the United States is",
]
# The LMCache config is written INLINE -- no yaml, no env file. Keys with the
# `lmcache.` prefix are forwarded into LMCache's own config.
ktc = KVTransferConfig(
kv_connector="LMCacheConnectorV1",
kv_role="kv_both",
kv_connector_extra_config={
"lmcache.chunk_size": 256, # tokens per KV chunk — the unit of reuse
"lmcache.local_cpu": True, # hot tier in pinned CPU DRAM
"lmcache.max_local_cpu_size": 5.0, # GB (CPU tier only — no disk yet)
},
)
llm = LLM(
model="meta-llama/Llama-3.1-8B-Instruct",
kv_transfer_config=ktc,
enable_prefix_caching=False, # isolate LMCache as the reuse path (see note)
gpu_memory_utilization=0.85,
enforce_eager=True,
)
sp = SamplingParams(temperature=0.0, max_tokens=20)
out_a = llm.generate(prompts, sp) # Phase A: miss -> compute + store KV
out_b = llm.generate(prompts, sp) # Phase B: hit -> load KV, skip prefill
That's the entire surface a user sees: one kv_connector name, a kv_role, and a handful of lmcache.* config keys. This particular config wires up exactly one storage tier — the CPU hot cache (LocalCPUBackend) — which is also the first stop on our backend tour later. Everything else in this post is what happens behind these knobs.
We're using this example to show the mechanism, not to benchmark it. The thing to watch is LMCache's own log line, LMCache hit tokens: N, which is emitted from get_num_new_matched_tokens (vllm_v1_adapter.py:1328) each time the scheduler asks LMCache how much of a prompt it can supply. Running the script, those lines tell a clean story:
| request | phase | hit tokens |
|---|---|---|
| prompt 0 | A (first time) | 0 — nothing cached yet |
| prompt 1 | A (first time) | 512 — reuses prompt 0's just-stored shared prefix |
| prompt 0 / 1 | B (second pass) | 512 / 512 — full prefix loaded back from the CPU tier |
Two things are worth pausing on. First, the within-batch hit on prompt 1 during Phase A: because both prompts share LONG_PREFIX, by the time prompt 1 is scheduled the chunks prompt 0 just produced are already in the cache. That cross-request reuse — not just repeat-request reuse — is the whole point of LMCache. Second, in Phase B the hit is genuinely served by LMCache, not by vLLM: with enable_prefix_caching=False vLLM has no GPU-side prefix cache to fall back on, so need to load: 512 means the KV is physically loaded back from LMCache's CPU tier into the paged buffer.
So in this example, two things happen around every engine step: before the forward pass, LMCache tries to load matching KV into vLLM's paged buffer; after the forward pass, it saves newly computed KV back out. Let's see where vLLM calls into LMCache to make that happen.
The master map: one step, twelve arrows
vLLM's connector interface is split across the two halves of the engine we met in the recap: the scheduler (decides what runs, allocates blocks) and the worker (runs the forward pass on the GPU). LMCache implements both halves. The class vLLM instantiates is LMCacheConnectorV1Dynamic (lmcache_connector_v1.py:30), a thin shim that forwards every call to LMCacheConnectorV1Impl (vllm_v1_adapter.py:442), where the real work lives.
Before any details, it helps to fix who calls whom, when — because LMCache never calls vLLM; it only ever gets called. vLLM builds the connector from your kv_transfer_config, and it builds two separate instances:
- a scheduler-side instance, constructed in the scheduler's
__init__withrole=SCHEDULER(scheduler.py:128). This one has no GPU; it only answers lookup questions and packs metadata. - a worker-side instance, one per worker, constructed after KV-cache init with
role=WORKER(gpu_worker.py:529→kv_transfer_state.py:67). This one has the GPU and does the actual KV movement.
Within one engine step, everything that passes between vLLM, the two connector instances, and LMCache's storage fits in one sequence diagram. This diagram is the spine of the post — every section from here on is one (or two) of its numbered steps, walked in order:
In words, the twelve steps group like this:
| steps | where | call | in one line |
|---|---|---|---|
| ①–② | scheduler | get_num_new_matched_tokens | "how many leading tokens can you supply?" — the lookup |
| ③ | scheduler | update_state_after_alloc | blocks allocated → commit the hit |
| ④–⑤ | scheduler | build_connector_meta | pack the step's load/save plan, attach it to SchedulerOutput |
| ⑥ | — | (transport) | the plan crosses to the worker process |
| ⑦ | worker | start_load_kv | execute the load: scatter hit KV into the paged buffer |
| ⑧–⑨ | LMCache | retrieve | StorageManager finds the chunks across tiers and serves them |
| ⑩ | worker | model forward | compute; in layerwise mode, also pump per-layer load/save |
| ⑪–⑫ | worker | wait_for_save | execute the save: gather new KV out, hand it to the tiers |
The scheduler side runs in the engine-core process (no GPU) — it decides. The worker side runs next to the GPU — it moves bytes. The connector metadata (steps ④–⑥) is the only channel between them. One more hook exists outside the loop: register_kv_caches, called once at startup, which hands the worker-side connector the real GPU tensors; we'll meet it just before step ⑦.
Steps ①–② — the lookup: get_num_new_matched_tokens
This is the step that discovers a hit, so it's worth following all the way down. Its job is to answer one question for the scheduler: beyond the num_computed_tokens vLLM can already serve from its own GPU prefix cache, how many more leading tokens can LMCache supply? The answer is a delta — need_to_allocate = num_external_hit_tokens − num_computed_tokens (vllm_v1_adapter.py:1303).
To produce that number, the connector calls lookup_client.lookup(token_ids, req_id), and four ideas stack up inside it.
1. Chunking. LMCache doesn't key KV by individual token — it keys by fixed-size chunks (chunk_size, default 256). So the first thing lookup does is split the prompt into chunks (ChunkedTokenDatabase._chunk_tokens, token_database.py:305). A 1000-token prompt becomes 3 full chunks; the trailing 232-token remainder is dropped (a partial chunk's key could never match the eventual full chunk, so storing or looking it up would be pointless). This is why you saw hit counts land on clean multiples of 256 in the running example.
2. A chained "prefix hash." Each chunk's key is not hash(chunk_tokens). It's folded from the previous chunk's hash (_prefix_hash, token_database.py:329):
prefix_hash = self._get_init_hash()
for token_chunk in token_chunks:
prefix_hash = self._hash_tokens(token_chunk, prefix_hash) # ← previous chunk's hash folded in
yield prefix_hash
So chunk 3's key depends on chunks 0,1,2,3 — it identifies the entire prefix up to that point, not just the chunk's own tokens.
This is the analogue of vLLM's chained block hashes from the recap, just at 256-token granularity instead of 16. The consequence is the whole reason the lookup can return a single number: a hit on chunk N's hash guarantees the full prefix 0..N matched, so the server simply counts the leading run of hits and stops at the first miss — a partial/middle hit is useless because vLLM can only consume a contiguous prefix. The figure's counter-example shows the flip side: two prompts that share byte-identical later chunks get different prefix hashes for them, because their first chunk differs.
3. It's a delegated lookup — the keys travel to the data. The scheduler-side connector has no GPU, no LMCacheEngine, and no storage tiers; those live with the workers. So lookup doesn't search anything itself — it ships the list of prefix hashes over an RPC to the worker-side lookup server (send_and_recv_all, lmcache_lookup_client.py:129), the side that actually holds the KV. On the worker, that server hands the hashes to LMCacheEngine.lookup (cache_engine.py:1093), which does three things:
- rehydrates keys — turns each incoming hash back into a
CacheEngineKey(it trusts the client's precomputed hashes rather than re-hashing tokens); - walks the tiers — calls
storage_manager.batched_contains(keys, pin=True)(:1192), the prefix-assignment-across-tiers search we'll dissect at steps ⑧–⑨, which returns how many contiguous leading chunks are present. Note thepin=True: looking a chunk up also pins it — hold that thought; - converts chunks → tokens — and this is the neat part: it doesn't sum anything; it just keeps the
endoffset of the last hit chunk (res = end,:1200-1202). Because chunks are a contiguous prefix starting at token 0, the end offset of the last hit chunk is the matched token count. That integer travels back (as a 4-byte int) and becomes the step-② answer.
4. Min across workers. Under tensor/pipeline parallelism each worker holds only a shard of every token's KV (some heads / some layers). A token is only recoverable if every worker still has its shard, so the client sends to all ranks and takes num_hit_toks = min(results) (:147) — the usable prefix is bounded by the worst-off worker.
So that's how the number is produced: chunk the prompt, chain-hash each chunk, fan the hashes out to every worker, take the min. But the same hook has a second story — not what it computes, but how it behaves when the scheduler calls it again and again for one request. That story is about the pin=True we flagged, and it has two halves.
Why pin at all? There's a gap of several steps between this lookup (where the scheduler discovers the hit) and step ⑦ (where the worker actually loads the KV). The scheduler is about to be promised "N tokens are available," and that promise has to still hold when the load finally happens. A pin is a do-not-evict reservation that keeps the matched chunks alive across that gap; the engine records them under this lookup (lookup_pins[lookup_id], :1199). (What a pin physically is — step ⑪.)
Why idempotent? The scheduler may run this step for the same request many times: a request can sit in the waiting queue for several steps before enough blocks free up, and a preempted request re-enters scheduling later. But the lookup is expensive (chunk + hash + fan-out to every worker), and — as we just saw — it pins. If each repeated call re-ran everything, it would re-pin the same chunks every step, and the pin counter would never balance — a slow leak. So LMCache caches the result per request id (lookup_cache(req_id), vllm_v1_adapter.py:1255): a repeat call returns the cached answer without re-running the lookup or pinning a second time. The cache clears once the request is actually scheduled (step ③); the pin releases at step ⑪.
Both the idempotency above and one more detail below come from the same fact: a request's life in the scheduler isn't one clean pass — it can wait, and it can be preempted and resumed. Idempotency was the caching-side consequence of that. There's also an input-side one, in what gets hashed: request.all_token_ids, not request.prompt_token_ids (:1269). A request that ran for a while and was then preempted has already generated tokens past its original prompt, so when it resumes, the KV worth recovering covers that whole grown span — prompt plus everything decoded so far. Hashing all_token_ids makes the key span those tokens too; hashing only the prompt would leave the generated tail uncacheable.
One last wrinkle: when LMCache has the entire prompt cached, it deliberately reports one token short — if num_external_hit_tokens == request.num_tokens: need_to_allocate -= 1 (:1306). The reason is subtle but important: a KV cache stores each token's K and V (the context it offers to other tokens), not the logits (the prediction of the next token). If you loaded 100% of the prompt's KV and ran zero forward steps, you'd have perfect context but no hidden state at the last position to turn into logits — nothing to sample the first output token from. Leaving the last token to be computed forces exactly one column of forward pass to regenerate those logits. This is the same "recompute the last token on a full hit" rule vLLM applies to its own prefix cache.
Step ③ — the commit: update_state_after_alloc
If steps ①–② propose a hit, step ③ commits it. The two are the halves of a two-phase commit, and the reason they're split is visible only in vLLM's scheduler. Inside schedule(), each waiting request is processed like this (scheduler.py):
get_num_new_matched_tokens(req) # steps ①–② — propose (:618)
│
allocate_slots(req, num_new_tokens) # the real decision — CAN FAIL (:761)
│ └── returns None (no free blocks) ──► break: request stays WAITING
▼
update_state_after_alloc(req, ...) # step ③ — commit (:787)
│
pop from waiting → self.running.append(req) (:803, :826)
The scheduler calls the lookup before it knows whether it can fit the request, and allocate_slots in between can genuinely fail — there may not be enough free blocks, in which case the request is left in the waiting queue and re-examined next step. That is exactly why the lookup had to be idempotent: the retry must not re-pin. Step ③ runs only on the success path, so it's the connector's signal that "this request is really going to run." Its core is a single latch flip: the LoadSpec that the lookup recorded with can_load=False gets set to can_load=True (vllm_v1_adapter.py:1424). That flag is what the worker checks later, at step ⑦, to decide whether to actually pull KV in.
Three more things happen here, all of them "commit" bookkeeping:
- It releases the lookup's idempotency cache. The first line is
clear_lookup_status(req_id)(:1365). This is safe precisely because the request is about to leave the waiting queue forself.running— and the lookup only ever runs in the waiting loop, so this request will never be probed again. (Note this clears only the cached lookup result; the KV pin is released much later, at step ⑪.) - It cross-checks the two sides' arithmetic. An assertion (
:1408) requires the scheduler'snum_external_tokensto equal LMCache's ownlmcache_cached_tokens − vllm_cached_tokens − recalc_last, whererecalc_lastis the 1 token dropped on a full hit. It's a guard that the number the scheduler allocated blocks for is exactly the number LMCache intends to load — the two bookkeepers must agree. - It stashes the request for later steps.
_unfinished_requests[req_id] = request(:1389) keeps the vLLMRequestobject around sobuild_connector_metaandrequest_finishedcan reach it.
There are two early outs: if the lookup never recorded a LoadSpec for this request (no external hit at all), or if the scheduler reports num_external_tokens == 0, step ③ simply leaves can_load=False and returns — nothing to load.
Steps ④–⑤ — packing the plan: build_connector_meta
Steps ①–③ ran on the scheduler and left their decisions in scheduler-side dicts (load_specs, _request_trackers). But the worker is what actually moves KV, and it's a different connector instance — in general a different process — with no access to those dicts. So at the end of schedule() (scheduler.py:963), build_connector_meta serializes the step's plan into one object (step ④) and attaches it to the SchedulerOutput (step ⑤).
Its shape is simple: LMCacheConnectorMetadata is just a list[ReqMeta], one ReqMeta per request scheduled this step. Each ReqMeta is that request's per-step to-do list for the worker:
ReqMeta
├── req_id
├── token_ids # the tokens in play this step
├── slot_mapping # token i -> physical slot in the paged buffer (interlude below)
├── is_last_prefill
├── load_spec : LoadSpec{ vllm_cached_tokens, lmcache_cached_tokens, can_load } # what to load
└── save_spec : SaveSpec{ skip_leading_tokens, can_save } # what to save
The load half was settled at steps ①–③. Building each ReqMeta (in ReqMeta.from_request_tracker, vllm_v1_adapter.py:293) is where the save plan is decided, and it follows three rules:
-
Incremental. A request is stored across many steps, so re-storing its whole prefix every step would be quadratic waste. The connector tracks
num_saved_tokenson theRequestTrackerand setsskip_leading_tokensto it (:328), so each step stores only the new tail. Inmetadata_demo.pyyou can watch this live: across two prefill steps of one request,skip_leading_tokensadvances0 → 4, so step 2 stores only tokens 4-7 and never re-stores 0-3. -
Chunk-aligned.
num_tokens_to_saveis rounded down to a chunk boundary (:353-356) — a partial chunk is never stored, because its key would differ from the eventual full chunk and could never be matched on lookup. Same "chunk is the unit" rule we saw at step ①, now on the write side. -
Skip decode by default. If the request is in its decode phase, saving is skipped unless
save_decode_cacheis set (:340). The reasoning: a prompt prefix is often shared across requests (a system prompt, a document, a few-shot template) and worth caching; a model's generated continuation is usually unique to that request and rarely re-hit, so storing it costs more than it returns.
Two request flavors feed this loop, and the only real difference is tracker lifecycle: new requests (scheduled_new_reqs, :1453) are first-time prefills, so RequestTracker.from_new_request creates the tracker; cached requests (scheduled_cached_reqs, :1492) are already running (decode) or resumed from preemption, so tracker.update(...) appends the new tokens/blocks. Both then run through ReqMeta.from_request_tracker. The RequestTracker is the persistent accumulator — it carries token_ids, block_ids, and num_saved_tokens across steps; the ReqMeta is the per-step snapshot derived from it. "Derived," not "copied": the block_ids and num_saved_tokens you'd expect aren't in the ReqMeta struct above, because they've been transformed into the fields that are. The block_ids become slot_mapping (slot = block_id × block_size + offset, the interlude below); num_saved_tokens becomes save_spec.skip_leading_tokens (the incremental rule above). The snapshot carries the results of the tracker's state, not the raw state.
So step ④ has produced one serializable object, and step ⑤ has set it on the SchedulerOutput. But it's still sitting in the scheduler process. Step ⑥ is how it crosses the gap.
Step ⑥ — the plan ships to the worker
The attach (step ⑤) costs nothing. The return value of build_connector_meta doesn't get its own message. It's set as a single field on the SchedulerOutput the scheduler was going to send anyway (scheduler.py:956):
meta = self._build_kv_connector_meta(self.connector, scheduler_output)
scheduler_output.kv_connector_metadata = meta # one field, free ride
But there's a deeper reason it has to ride this way. Recall the two connector instances: one role=SCHEDULER in the engine-core process, one role=WORKER per worker process — different OS processes with different address spaces. The scheduler-side dicts (load_specs, _request_trackers) are invisible to the worker. So this metadata field isn't just a channel between the two instances — it's the only one. Anything the scheduler decided this step that the worker needs to know must be serialized into it.
The ship (step ⑥) depends on deployment. The engine hands the whole SchedulerOutput to the executor (core.py:455):
- Production / multi-process (
vllm servewith real worker processes): the call routes throughcollective_rpc, which enqueues onto a shared-memory message queue (multiproc_executor.py:374). That queue pickles the object (protocol 5,shm_broadcast.py:743) into a ring buffer, and each worker process dequeues and un-pickles its own copy (:790). TheSchedulerOutput—kv_connector_metadataand all — is deep-copied across the process boundary. - Single-process (our
LLM(...)example,UniProcExecutor): the worker is in the same process, so the object is passed by reference — no serialization at all.
The single-process case is the teaching crutch; production is the multi-process path, and it forces a constraint that quietly shapes the entire metadata design.
The pickle constraint: the plan carries only a plan. Because the metadata must survive pickle.dumps → bytes → pickle.loads in another process, it can only hold things that are meaningful as plain data on the far side:
Can it ride in ReqMeta? | Why |
|---|---|
slot_mapping — a CPU int64 tensor | ✅ pure data; pickles to bytes, rebuilds identically |
LoadSpec / SaveSpec — small int structs | ✅ pure data |
| a GPU tensor / raw CUDA pointer | ❌ a pointer is just an integer valid only in one process's CUDA context; the other process has neither that memory nor that context. (Even pickling a CUDA tensor silently copies it to host — you'd be shipping KV every step, which is the opposite of the point.) |
So the cross-process channel carries an address book (slot_mapping — "token i's KV belongs in slot s") and an instruction sheet (the load/save specs). It deliberately carries no KV bytes and no GPU references.
Then where do the real GPU tensors come from? From a completely separate, worker-local path — the startup hook register_kv_caches, which we open in the interlude below. The division of labor:
| Scheduler-side connector (engine-core proc) | Worker-side connector (worker proc) | |
|---|---|---|
| Knows | logical: block_ids, derived slot integers | physical: real GPU KV tensors [num_blocks, block_size, n_kv_heads, head_size] ×layers |
| Touches GPU memory? | never | yes, locally |
| Acquired how | computed each step | register_kv_caches, once at startup |
The integer 20 crosses the boundary (in slot_mapping); the memory slot 20 names never does. The two sides agree only on an indexing convention — slot = block_id × block_size + offset. The worker inverts it with divmod: with our toy block_size=4, slot 20 decodes to divmod(20, 4) = (block_id=5, offset=0). Those two numbers index the first two axes of a layer's KV tensor (shape [num_blocks, block_size, n_kv_heads, head_size]), so slot 20's KV lives at layer_tensor[5, 0]. And because every layer shares the same paging, it's [5, 0] in all 32 per-layer tensors — one decode, 32 destinations.
Binding, and the lifecycle latch. When the worker's execute_model runs, it binds this step's metadata (bind_connector_metadata, mixin:89) so the worker-side hooks can reach the plan. After the forward pass and wait_for_save, it clears it again (clear_connector_metadata, mixin:112) so the next step starts clean. Bind-before, clear-after: the plan is live only for the duration of one execute_model.
With the plan now bound on the worker, the worker can act on it. But before step ⑦ we need its two working tools — the per-token address book the plan carries, and the GPU tensors registered at startup.
Interlude: the two address books
slot_mapping: from block table to scatter/gather
One object threads through three steps: step ④ builds it, step ⑦ uses it to load, step ⑪ uses it to save. slot_mapping is the address book that says where in vLLM's GPU buffer each of a request's tokens keeps its KV.
The problem it solves: a request's tokens are logically contiguous (token 0, 1, 2, …), but vLLM's KV cache is paged — the scheduler hands the request a block table of scattered physical blocks (e.g. [5, 2]), pulled from wherever the free_block_queue had room. So token 0's KV and token 4's KV can land in completely different parts of the buffer.
Construction (step ④). Inside ReqMeta.from_request_tracker, LMCache builds its own slot_mapping from the request's allocated_block_ids and block_size. This is the code, verbatim (vllm_v1_adapter.py:396-403):
num_blocks = len(tracker.allocated_block_ids)
# ...
block_ids = torch.tensor(tracker.allocated_block_ids, dtype=torch.long)
block_offsets = torch.arange(0, block_size, dtype=torch.long)
slot_mapping = (
block_offsets.reshape((1, block_size))
+ block_ids.reshape((num_blocks, 1)) * block_size
)
slot_mapping = slot_mapping.flatten()[: len(token_ids)]
The whole thing is just the rule slot = block_id * block_size + offset, vectorized via broadcasting. Take block table [5, 2], block_size=4, 6 tokens. Block 5 starts at slot 5×4 = 20, block 2 at slot 2×4 = 8, so the result looks like this:
token i : 0 1 2 3 4 5
slot_mapping : 20 21 22 23 8 9
└──── block 5 ──┘ └block 2┘
That is the whole shape of slot_mapping: a flat 1-D tensor, one entry per token, where token i's KV belongs in slot slot_mapping[i]. The jump from 23 down to 8 between token 3 and token 4 is the paging showing through — logically consecutive tokens, physically discontiguous slots. (Block 2 is only half-used here: its slots 10, 11 exist but belong to tokens not generated yet, so the final [: len(token_ids)] truncates them off.) This is LMCache's own copy, computed from the block table it tracks — the same values as vLLM's forward-pass slot mapping, built independently.
The figure shows the property everything downstream relies on: a chunk is contiguous in index space (slot_mapping[start:end] is a clean slice) but scattered in physical space (the values in that slice span several blocks). We'll meet this again at step ⑨, where it's the crux of how chunks meet paged blocks.
The destination is shared, not copied. Where does the load write? Into vLLM's actual per-layer KV tensors — one per transformer layer (32 for Llama-8B), each shaped [num_blocks, block_size, …], where a "slot" indexes the flattened first two dims. At startup vLLM hands LMCache these exact tensors via register_kv_caches (next subsection), and LMCache just stores the reference — no copy. This sharing is the crux: the model's attention reads KV only from these bound tensors, by slot, so when LMCache writes loaded KV into slot 20 of each layer tensor, the forward pass finds it there and skips recomputing it.
Load and save are the same kernel, opposite directions. The worker drives both through one custom CUDA op, lmc_ops.multi_layer_kv_transfer, which touches all layers at once. Loading (to_gpu, gpu_connectors.py:318) passes TransferDirection.H2D:
lmc_ops.multi_layer_kv_transfer(
memory_obj.tensor, # the fetched KV (contiguous, per token)
kv_cache_pointers, # vLLM's per-layer paged tensors (shared)
slot_mapping[start:end], # where each token's KV goes
self.device, self.page_buffer_size,
lmc_ops.TransferDirection.H2D, # host -> device: scatter in
self.gpu_kv_format,
block_size=self.block_size, head_size=self.head_size,
skip_prefix_n_tokens=skip_prefix_n_tokens,
)
Saving (from_gpu, gpu_connectors.py:366) is the identical call with TransferDirection.D2H — same slot_mapping, the KV gathered out of the paged tensors instead of scattered in. So one map, two directions: H2D scatters fetched KV into the scattered slots on load (step ⑨); D2H gathers KV out of those slots on save (step ⑫).
register_kv_caches: the startup wiring
slot_mapping is the per-token column coordinate. The scatter kernel needs a second coordinate — which layer — plus the physical tensors themselves. Both come from register_kv_caches, which runs once, at startup, worker-side only (gpu_model_runner.py:7340, via the shim at lmcache_connector_v1.py:50 → vllm_v1_adapter.py:731).
Where the tensors come from — and why they're the real ones. The dict it receives is built moments earlier in vLLM's own initialize_kv_cache_tensors (gpu_model_runner.py:7201), in exactly the three steps from the recap:
kv_cache_raw_tensors = self._allocate_kv_cache_tensors(...) # :7233 allocate raw VRAM
kv_caches = self._reshape_kv_cache_tensors(...) # :7236 -> {layer: [num_blocks, block_size, …]}
bind_kv_cache(kv_caches, ..., self.kv_caches, ...) # :7248 BIND into the attention layers
... ; kv_transfer_group.register_kv_caches(kv_caches) # :7340 hand the SAME dict to LMCache
The crucial line is bind_kv_cache: it wires these exact tensors into the model's attention modules, so the forward pass reads and writes KV from these very buffers. Then the same dict is handed to LMCache, which stores the reference (self.kv_caches = kv_caches, :736) — no copy, for the reason explained above.
The per-layer pointer table — the second address book. Here's the catch: slot_mapping is only half an address. A token's KV isn't one tensor — with 32 layers it's 32 separate (K,V) pieces, one in each layer's own tensor. And all 32 layers share the request's block table, so slot_mapping decodes to the same within-tensor position in every layer: token 0's KV sits at slot 20 of layer 0's tensor, slot 20 of layer 1's tensor, … slot 20 in all 32. So slot_mapping[i] tells the kernel which slot, but not which layer's tensor — for that it needs the 32 per-layer base addresses. register_kv_caches captures them once (_initialize_pointers, gpu_connectors.py:238):
self.kv_cache_pointers.numpy()[:] = [t.data_ptr() for t in kv_caches] # 32 per-layer base addresses
self.kv_cache_pointers_on_gpu[idx].copy_(self.kv_cache_pointers) # ... resident on the GPU
It's built once because the 32 layer tensors are allocated at startup and never move — their base addresses are constant; only slot_mapping (the per-request column) changes step to step. Both tables ride into the fused kernel:
lmc_ops.multi_layer_kv_transfer(
memory_obj.tensor, # the chunk's KV
kv_cache_pointers, # WHICH LAYER — 32 base addresses (built once, here)
slot_mapping[start:end], # WHICH SLOT — per token (built each step, in ReqMeta)
...)
so a single launch fills the whole (layer × token) grid — token i, layer L lands at kv_cache_pointers[L] + slot_mapping[i]×slot_size — instead of 32 separate per-layer copies. (register_kv_caches finishes with self._manager.post_init(), :738, which finalizes the engine/backends now that the real buffer's pointers and shapes are known.)
The figure is the whole interlude in one frame: the column is slot_mapping (which slot, rebuilt every step), the row is the per-layer pointer table (which layer's tensor, built once), and a single multi_layer_kv_transfer launch fills every cell of the (layer × token) grid at once.
That's the toolbox. Now the worker-side steps, in diagram order.
Step ⑦ — start_load_kv: execute the load
This is the first worker-side step (vllm_v1_adapter.py:741), called on context-enter just before the forward pass (mixin:95). By now it holds both ingredients: this step's plan, just bound in (_get_connector_metadata(), :762), and the real per-layer GPU KV tensors from startup (self.kv_caches, :766). Its job is to walk the requests and, for each loadable one, scatter its hit KV into the paged buffer. Four things happen, and three of them are about correctness, not just movement.
The can_load gate (:792). The loop runs over every request in the metadata — but metadata.requests is not just the load list. Every scheduled request gets a ReqMeta because every one needs its new KV saved later; a request that had no hit at all is in the list purely for saving, with load_spec is None. So the loop opens with a filter:
if request.load_spec is None or not request.load_spec.can_load:
continue
The two skip cases map exactly onto the scheduler-side story: load_spec is None means the lookup found nothing (save-only request); can_load is False means steps ①–② proposed a hit but step ③ never committed it (e.g. allocate_slots failed and the request stayed waiting). Only a request that survived the two-phase commit gets loaded.
The load mask: only fill the gap (:800-806). Two different "cached" counts are in play, and they're not the same cache:
load_spec.vllm_cached_tokens— tokens already in vLLM's own GPU prefix cache (thenum_computed_tokensfrom step ①). Already in GPU.load_spec.lmcache_cached_tokens— tokens LMCache's tiers can supply.
LMCache should fill only the [vllm_cached, lmcache_cached) gap — the part vLLM doesn't already have — so it masks the leading vllm_cached tokens out of the load:
token_mask = torch.ones(len(tokens), dtype=torch.bool)
masked_token_count = (
request.load_spec.vllm_cached_tokens // self._lmcache_chunk_size
* self._lmcache_chunk_size # floor to a chunk boundary
)
token_mask[:masked_token_count] = False
Retrieve and scatter (:839). With the mask in hand, the non-layerwise path does one bulk call:
ret_token_mask = self.lmcache_engine.retrieve(
tokens[:lmcache_cached_tokens],
token_mask[:lmcache_cached_tokens],
kvcaches=kvcaches, # vLLM's registered GPU tensors
slot_mapping=slot_mapping[:lmcache_cached_tokens],
...
)
This is where the slot_mapping work pays off: retrieve fetches the gap chunks from the tiers and scatters them into kvcaches at exactly the slots the map names, via the multi_layer_kv_transfer H2D kernel. Where those chunks come from — which tier, promoted from where — is steps ⑧–⑨, the next section.
Verify, and convert silent corruption into recompute (:850-875). Step ① pinned the matched KV so it couldn't be evicted — yet start_load_kv still checks the load defensively:
num_retrieved_tokens = ret_token_mask.sum().item()
num_expected_tokens = lmcache_cached_tokens - request.load_spec.vllm_cached_tokens
if num_retrieved_tokens < num_expected_tokens:
missing_blocks = self.record_failed_blocks(...) # :869
self._invalid_block_ids.update(missing_blocks)
The pin blocks eviction, but a load can still come up short for other reasons — a cold-tier disk read error, a remote-tier network drop, a corrupted chunk, an async race. And the cost of ignoring a shortfall is the worst kind: a slot that should have been filled still holds stale KV left by whatever request last used that recycled block, and attention does not validate the bytes it reads — it would compute a plausible-but-wrong result and silently corrupt the output. So LMCache makes the failure explicit. record_failed_blocks (:877) computes missing_mask = expected_mask & ~ret_mask (expected to load, didn't arrive), maps those token indices through slot_mapping // block_size to the set of block ids, and stashes them in self._invalid_block_ids. It aggregates to block granularity because a block is vLLM's atomic cache unit: one missing token taints the whole block, and a half-filled block can't be reused — it must be recomputed entire. That set later rides the reverse channel — output.invalid_block_ids = kv_connector.get_block_ids_with_load_errors() (mixin:105) — back to the scheduler, which tells vLLM to recompute those blocks. Silent wrong-answer becomes recompute-and-be-correct.
Layerwise: launch here, pump later (:809). The bulk path above loads all layers' KV before the forward starts. The use_layerwise path overlaps load with compute instead — but in start_load_kv this branch only launches the pipeline: it builds a retrieve_layer generator, primes the first two layers (next() twice), and stashes the generator in self.layerwise_retrievers. The actual per-layer pump runs from inside the forward pass — that's step ⑩, two sections down.
So start_load_kv discovers nothing and decides nothing — it executes the scheduler's committed plan, guards the result, and hands the "where do the bytes live" question to exactly one component: the StorageManager.
Steps ⑧–⑨ — retrieve: inside the StorageManager
This is the piece with no analogue in vLLM. vLLM has exactly one place KV lives (GPU paged memory) and one eviction story (free_block_queue). LMCache has a stack of tiers — CPU DRAM, local disk, GPUDirect SSD (and others) — and the StorageManager is what turns that stack into a single logical cache. Step ⑧ is the worker-side connector asking it for chunks; step ⑨ is the KV landing in the paged buffer.
First, a type distinction: allocator backends vs storage backends
The first thing to internalize is a two-level hierarchy (storage_backend/abstract_backend.py):
StorageBackendInterface— the base contract every tier implements:contains,get_blocking,batched_submit_put_task,remove,pin/unpin,close. A backend that only implements this is a place KV can be stored and fetched from.AllocatorBackendInterface(extends the above,:338) — addsallocate/batched_allocate. A backend that implements this additionally owns a pool of memory it can hand outMemoryObjs from.
Why the split? Because a KV chunk has to land somewhere on the way in and out of every tier, and different tiers want it to land in different memory:
| Backend | Interface | Where allocated chunks live | I/O path |
|---|---|---|---|
LocalCPUBackend | Allocator | its own pinned CPU DRAM pool | in-memory dict, synchronous |
LocalDiskBackend | Storage (reuses CPU's allocator) | — borrows LocalCPUBackend | async worker + priority queue, optional O_DIRECT |
GdsBackend | Allocator | its own GPU / cuFile-registered buffer | cuFile direct SSD↔GPU (falls back to mmap+memcpy) |
Notice LocalDiskBackend is the odd one out: it has no allocator of its own. When it needs a MemoryObj to read a chunk into, it calls get_allocator_backend(), which returns the shared LocalCPUBackend (local_disk_backend.py:639). Disk is a destination; the bytes still have to stage through CPU DRAM. GdsBackend, by contrast, brings its own memory because its whole reason for existing is to put the chunk somewhere special (directly in VRAM).
Retrieve in depth: from a chunk key to KV in the GPU
The body of LMCacheEngine.retrieve (cache_engine.py:775) — what step ⑦ called — turns "the scheduler says there's a prefix hit" into "the KV is physically sitting in vLLM's GPU paged buffer, at the right slots." It runs in four parts:
(a) The key is the address (_process_tokens_internal, :1670). Retrieve can't "search for token 4's KV" — there is no content search. It turns the tokens into chunk keys, and the key is where the KV lives:
for start, end, key in self.token_database.process_tokens(tokens=tokens, mask=mask):
chunk_infos.append((key, start, end)) # (key, token-span-start, token-span-end)
start, end are the chunk's span in token-index space; key is the chained prefix hash from step ① (wrapped in a CacheEngineKey with the model name). Because the key is computed from content, not request identity, two different requests whose prefix holds the same tokens compute the same key — which is exactly why one request can hit the KV another request stored. Matching is per-chunk and all-or-nothing: change one token in a chunk and its key changes, missing that chunk and everything after it.
(b) Search = prefix-assignment across tiers (get_block_mapping, storage_manager.py:973). The tiers are an OrderedDict of backends, hottest first. The search doesn't ask every tier about every key. It hands the full key list to the hot tier; that tier reports how many leading keys it has (batched_contains returns a contiguous-run count); those chunks are assigned to it, and only the remaining keys pass down to the next, colder tier:
This works because retrieval is always prefix-based (storage_manager.py:675): the deepest suffix chunks are the ones most likely to have been evicted from hot tiers down to cold ones, so the hottest tier naturally holds the prefix and colder tiers hold progressively deeper suffixes.
(c) Get = fetch the object, and two guards (batched_get, storage_manager.py:483). For each (tier, keys) pair the manager calls backend.get_blocking(key), which looks the key up in that tier's dict and returns the MemoryObj — after one important side effect (local_cpu_backend.py:214):
memory_obj = self.hot_cache[key]
memory_obj.ref_count_up() # hold it for the caller, so it can't be freed mid-use
return memory_obj
That ref_count is the second of two independent eviction guards, and it's worth seeing why both exist. can_evict is not is_pinned and ref_count == 1 (memory_management.py:673), so either counter blocks eviction. pin_count (step ①) is a cross-step reservation — "I looked this up, I'll load it a few steps later, don't evict it in between." ref_count (get_blocking) is an in-use guard for the immediate copy — between handing the object out and the H2D finishing its read, another thread's store could otherwise evict the chunk and hand its memory to a new allocation, and the in-flight copy would read garbage. The backend bumps ref_count itself because it's a self-contained primitive: it can't assume the engine happened to pin this chunk (the pin bookkeeping lives up in LMCacheEngine, invisible to the backend), and genuinely-unpinned objects do flow through here — a freshly promoted CPU copy, or a non-scheduler caller (P/D, the cache controller).
The get path also does promote-on-read: a hit served from a cold tier is written back into LocalCPUBackend (:514) so it's hot next time — the "read once, warm once" promotion that makes a stack of stores behave like one cache (the dashed green arrow in the figure).
(d) Scatter into the GPU — index-contiguous, value-scattered (step ⑨). retrieve accumulates a list of (key, memory_obj, start, end) it calls reordered_chunks (:874) — reordered because chunks come back grouped by tier (all of CPU's, then all of disk's), not in token order. That's fine, because each chunk carries its own (start, end), a self-contained "where do I go" label. The move is one call per chunk:
self.gpu_connector.batched_to_gpu(memory_objs, starts, ends, **kwargs)
# → for each chunk: to_gpu(memory_obj, start, end)
# → multi_layer_kv_transfer(memory_obj.tensor, kv_cache_pointers,
# slot_mapping[start:end], # ← the bridge
# TransferDirection.H2D, ...)
Here is where LMCache's chunk abstraction meets vLLM's scattered paged blocks, and it's the crux of the whole adaptation. A chunk is contiguous in slot_mapping's index space (slot_mapping[start:end] is a clean slice), but the values at those indices — the actual physical slots — can be anywhere, because slot_mapping was built from vLLM's scattered block table. So slot_mapping[start:end] of a single chunk is generally a scattered list of physical slots spanning several vLLM blocks, and the kernel scatters the chunk's KV one token at a time into them.
The figure is at real scale: a 256-token chunk is one contiguous slice on top, but its 16 block-sized segments land across 16 scattered blocks of the paged buffer — wherever the free_block_queue had room. The trick is that slot_mapping is indexed per token — not per chunk, not per block. The kernel simply walks the chunk's tokens one at a time and drops each into the slot its entry names; it never moves a whole chunk or fills a whole block at once. That dissolves both problems together: the 256-vs-16 size mismatch is irrelevant (nothing is copied chunk- or block-at-a-time), and so is the scattering (each token's destination is looked up on its own, so the slots can be anywhere). A chunk's boundaries never have to line up with a block's.
Step ⑩ — the model forward, and the layerwise pump
Step ⑦ left a thread hanging: in layerwise mode it only primed a generator — the real per-layer load is pumped from inside the forward pass. This is step ⑩ of the diagram, and seeing it means looking at vLLM's actual model code, which turns out to be refreshingly plain.
The forward is a for loop over layers. LlamaModel.forward (llama.py:395) embeds the tokens and threads one hidden_states tensor through the stack:
hidden_states = self.embed_input_ids(input_ids) # tokens -> h₀
for idx, layer in enumerate(self.layers): # :415 32 LlamaDecoderLayers, in order
hidden_states, residual = layer(positions, hidden_states, residual) # :418
hidden_states, _ = self.norm(hidden_states, residual) # -> lm_head -> logits
It's strictly sequential: layer L+1's input is layer L's output. Each LlamaDecoderLayer (:316) is norm → self_attn → norm → mlp, and only self_attn touches the KV cache (:328). One level down, LlamaAttention (:223) projects Q/K/V, applies RoPE, and calls self.attn(q, k, v) (:231) — which dispatches to unified_attention_with_output (attention.py:734), the function that actually reads the layer's cached KV and writes the new tokens' KV.
LMCache splices in without editing any of that — via a decorator. unified_attention_with_output is wrapped with @maybe_transfer_kv_layer (attention.py:733), which sandwiches the original call (kv_transfer_utils.py:51-57):
connector.wait_for_layer_load(layer_name) # entry: make layer L's KV present before attention reads it
result = func(*args, **kwargs) # the real attention compute for layer L
connector.save_kv_layer(layer_name, kv_cache, attn_metadata) # exit: hand layer L's fresh KV out to store
So every attention layer, on the way in and out, calls the connector — and for vanilla vLLM (no connector) the wrapper short-circuits to a plain func(*args, **kwargs), costing nothing.
Why this overlaps, and the bulk path can't. The compute chain is sequential and can't be parallelized — but loading layer L+1's KV is independent of layer L's compute (it just fills layer L+1's paged tensor from a tier). So the I/O can run ahead of the compute:
wait_for_layer_load is one step of a generator — next(layerwise_retriever) (vllm_v1_adapter.py:966) advances the load by exactly one layer — and step ⑦ already primed two layers (next() twice, :835). So by the time the forward reaches layer L and calls wait_for_layer_load(L), layer L is already loaded (the call returns at once), and that same next() kicks off loading a later layer to run behind the GPU's attention+MLP work on layer L. The loader stays a layer or two ahead, and the transfer hides in the compute's shadow.
save_kv_layer is the mirror image on the way out: it drives a store_layer generator (:1065, next() at :1078) so a layer's KV is handed off the moment it's computed, overlapping the store with later layers' compute; the trailing storers are flushed by wait_for_save — the next step. The non-layerwise path can't overlap at all — it does one bulk retrieve of all 32 layers before the forward starts, so the GPU sits idle through the entire transfer. Layerwise trades that idle time for pipelined I/O; non-layerwise is simpler and remains the default.
Steps ⑪–⑫ — wait_for_save: execute the save
This is the second worker-side step (vllm_v1_adapter.py:1081), called on context exit, right after the forward pass (mixin:100). It's the mirror image of step ⑦: it walks the same metadata.requests, applies a gate and a mask, moves slot_mapping to the device — then calls store (D2H, gather KV out of the paged buffer) where ⑦ called retrieve (H2D, scatter in). Step ⑪ is the call; step ⑫ is the gathered KV being handed to the StorageManager's write path. Three things distinguish the save side, plus the write path itself.
The save mask is the load mask's mirror. Same structure, mirrored meaning:
LOAD ⑦ (token_mask) | SAVE ⑪ (store_mask) | |
|---|---|---|
| skip the leading | vllm_cached_tokens | skip_leading_tokens (:1134) |
| sourced from | what vLLM's GPU cache already has | what LMCache has already saved (step ④'s num_saved_tokens) |
| floor to chunk | ✅ | ✅ (:1144) |
| meaning | "already in GPU, don't re-load" | "already in tiers, don't re-save" |
The "wait" is a real barrier, and it's about block reuse. The method is wait_FOR_save because the D2H gather reads KV out of vLLM's GPU paged blocks, and the instant this step ends the engine may hand those very blocks (back via free_block_queue) to a different request that writes new KV into them. If the gather were left to run lazily, that writer would race it and the gather would read a mix of old and new bytes — saving a corrupt chunk, which a future lookup would then serve as silently-wrong KV (the save-side twin of ⑦'s stale-read hazard). So wait_for_save blocks until the KV has been safely read out of vLLM's blocks (into LMCache's own MemoryObj); the slow part — persisting that MemoryObj to disk or a remote tier — may continue in the background.
Releasing the pin — and what a pin actually is. The loop's first act for every request, before the save gate, is self.lmcache_engine.lookup_unpin(request.req_id) (:1117). This closes the thread opened all the way back at step ①, and it's worth seeing what the pin physically is:
A KV chunk in a tier is a MemoryObj carrying a pin_count (memory_management.py:128); pin() increments it (:590). The LRU backend's victim-picker, get_evict_candidates, walks the hot_cache OrderedDict from its least-recently-used front and skips any chunk whose can_evict is false (lru.py:75) — and can_evict is not is_pinned and ref_count == 1 (memory_management.py:673). So a pin is not a lock: it neither moves nor holds the chunk; it just makes the eviction loop step over it. Step ① pinned the matched chunks precisely so they survive eviction during the several steps between the scheduler's lookup and the worker's load. wait_for_save is the single guaranteed-to-run point (the context manager's finally) where that pin is balanced — for every request, even consumer/no-save ones (:1094), because pin_count is a counter and an unbalanced pin leaves the chunk can_evict == False forever → permanently skipped → a slow memory leak that eventually starves allocation.
Step ⑫ — the write path, and why each tier copies. The gathered chunks now hit batched_put (storage_manager.py:384), where the "who owns the memory" axis becomes concrete. The KV chunks arrive as MemoryObjs allocated from the default (CPU) allocator. To store them into a tier whose allocator is different — say GDS's cuFile VRAM buffer — the manager must first allocate a fresh MemoryObj in that tier's memory and copy into it (allocate_and_copy_objects, :63, on a dedicated CUDA stream). Tiers that share the CPU allocator (like disk) skip the copy entirely — they're handed the same objects. The allocator a backend chooses dictates whether a put is a free hand-off or a real cross-device copy.
So the worker side, like the scheduler side, is narrow: ⑦ executes the committed load and guards it, ⑪–⑫ execute the incremental save, release the pin, and block until vLLM's blocks are safe to reuse — while every question of where the chunks live stays delegated to the StorageManager. The diagram is now fully walked. Everything left is detail — specifically, what each individual tier does with a chunk once it owns it. That's the backend tour.
The backend tour
The StorageManager told us that a chunk lands in some tier; this tour is what each tier physically does with it. We go CPU → Disk → GDS, coldest mechanisms building on the hottest, and we ask each backend the same two questions: where does its memory come from (does it own an allocator, or borrow one?), and how does I/O actually move a chunk in and out. We start with LocalCPUBackend, because the others lean on it.
Stop 1 — LocalCPUBackend: the pinned pool everything stages through
It's tempting to file this under "the hot tier" and move on, but it has three jobs, and only one of them is caching. It's also the default allocator for the entire engine and the pinned staging buffer every other tier's GPU traffic passes through — which is why, even when you set local_cpu: False, the backend is still constructed (local_cpu_backend.py:40). Caching it can skip; allocating and staging it cannot.
One pre-allocated, page-locked pool. Two things define this pool, and the figure shows both: it is one buffer carved into slices, and that buffer is pinned.
-
Up top — one buffer, sliced. At startup
initialize_allocator(:351) reserves a single buffer ofmax_local_cpu_sizeGB. Every chunk's CPU bytes are just a slice of it:MemoryObjMetadata.address/phy_sizeare nothing but an offset and a length into that one buffer (the labeled regions across the top of the figure). A chunk never gets its ownmalloc— it lives in a region of the pool. So the whole memory model collapses to one rule: pool full → evict a slice to make room. -
Down below — why pinned. The buffer is page-locked (pinned):
_allocate_cpu_memory(memory_management.py:415) gets it fromcudaHostAlloc(csrc/mem_alloc.cpp:15) and wraps the pointer as a zero-copytorch.frombufferview. The two rows of the figure show what that buys. A pinned pool is DMA-ready — the GPU's DMA engine reads it directly, one hop (the green row). Ordinary pageablemallocmemory is not DMA-able: CUDA must first copy it into a hidden internal bounce buffer, then DMA from there — two hops, an extra copy on every transfer (the red row). Finally,_resolve_pinned_alloc_free(:374) picks one of three flavors: plaincudaHostAlloc, a NUMA-bound variant on the RAM node nearest the GPU (so the DMA doesn't cross the inter-socket link), or a shared-memory variant so another process can map the same physical pool by name (P/D / disaggregation).
The default allocator — load-bearing even when "off." This is what makes it the core, not just the fastest tier. Most backends don't own memory: LocalDiskBackend has no allocator and calls get_allocator_backend() → LocalCPUBackend (local_disk_backend.py:639). So a chunk read off an SSD lands first in a slice of this pinned pool, and only then DMAs to the GPU — and because that slice is pinned, the CPU→GPU leg is the fast direct path. Whatever cold tier you bolt on, its last hop to the GPU can stage through this one pinned pool, and it's fast for all of them for the same reason.
Synchronous put. submit_put_task (:141) is just a guarded dict insert: dedup-check, ref_count_up, hot_cache[key] = memory_obj, update the LRU. No background thread — so a chunk stored this step is immediately visible to a contains/get the same step (which is exactly why the running example's prompt 1 hits prompt 0's just-stored prefix with no flush wait). A cold tier with an async writer can't promise that: between enqueue and the bytes landing, contains would miss, which is why the interface pairs it with exists_in_put_tasks (:135) — LocalCPUBackend returns False there because it has no in-flight queue; disk will not.
So LocalCPUBackend is the floor the rest of the tour stands on: a pinned slab that doubles as the engine's allocator and as the universal GPU staging buffer. The colder tiers are mostly variations on "where do the bytes really rest, and how do they reach this pool." Disk is next.
Stop 2 — LocalDiskBackend: index in RAM, data on disk
LocalDiskBackend (local_disk_backend.py:97) is the same skeleton as the CPU backend with four deliberate differences, and each one is a lesson in what changes when the data no longer fits in RAM.
① The index is in RAM; the data is on disk. The CPU backend's hot_cache mapped key → MemoryObj (the KV itself, in the pinned pool). Disk's self.dict maps key → DiskCacheMetadata — just the file path, size, shape, dtype — not the bytes. The bytes are a file, one per chunk: _key_to_path (:178) is <dir>/<key-string>.pt. The payoff is that contains (:180) is a pure in-RAM dict check — it never touches the disk. That matters because the retrieve search (get_block_mapping, step ⑧) calls batched_contains on every tier; if "is it there?" meant a disk read, searching a large cold tier would be ruinous. So "is it present?" stays a RAM operation no matter how big or slow the backing store is; disk I/O happens only on the actual get.
② It owns no memory — reads stage through the borrowed CPU pool. Disk is a plain StorageBackendInterface, not an allocator; get_allocator_backend() returns the shared LocalCPUBackend (:639). So load_bytes_from_disk (:568) does memory_obj = self.local_cpu_backend.allocate(...) and reads the file into that slice of the pinned pool. A disk hit therefore materializes as a CPU MemoryObj — which is exactly the object the StorageManager's promote-on-read then registers in hot_cache, so one disk read both serves the request and warms CPU. And because the landing buffer is pinned, the subsequent hop to the GPU is the fast direct-DMA path from Stop 1.
③ Writes are asynchronous. This is the sharpest break from CPU's synchronous dict insert, and it opens a timing gap the figure makes concrete:
The caller thread (green, top). submit_put_task (:291) does only quick bookkeeping — mark the key in-flight (insert_put_task), run disk-space eviction if the chunk would overflow max_local_disk_size (the same LRU get_evict_candidates, except "evict" = os.remove the file), bump the source's ref_count so the pinned slice can't be reused mid-write — then hands the write to a background pool (AsyncPQThreadPoolExecutor, 4 workers, a priority queue where prefetch < delete < put) and returns immediately. The bytes are not on disk yet.
The background worker (blue, below). async_save_bytes_to_disk (:491) runs later: it writes the file, and only at the end calls insert_key (add to the index) then remove_put_task.
The in-flight window (the shaded band). Between those two moments the chunk is mid-write — written by nobody's clock you control, and not yet in self.dict. A lookup landing inside the band sees contains() = False but exists_in_put_tasks() = True.
④ O_DIRECT (optional) bypasses the page cache. Normal buffered I/O routes through the kernel page cache; write_file/read_file (:593, :609) can instead open with O_DIRECT to DMA straight between the buffer and the device. The motivation is specific to a KV cache: LMCache already tiers its own hot data in the pinned CPU pool, so letting the kernel also cache gigabytes of KV file pages is a redundant copy, redundant RAM, and page-cache pollution that evicts other processes' working sets. O_DIRECT's cost is alignment: direct DMA moves whole device blocks, so the transfer size, file offset, and buffer address must all be multiples of the FS block size (os_disk_bs = statvfs.f_bsize, :133) — which is why the code gates on size % self.os_disk_bs == 0 and otherwise falls back to buffered I/O. O_DIRECT is also the conceptual ancestor of the GDS tier: both bypass the page cache for direct buffer↔device DMA; GDS goes one further and skips the CPU entirely.
So disk keeps the CPU backend's cache machinery (LRU index, pin/ref, eviction) but relocates the bytes to files, pays for it with an async writer and an in-flight window, stages every read back through the pinned pool, and optionally goes around the page cache. The next tier keeps this "index/metadata here, bytes elsewhere" shape but makes "elsewhere" an SSD wired straight to the GPU.
Stop 3 — GdsBackend: SSD↔GPU direct, when the hardware allows
GDS (GPUDirect Storage, via NVIDIA's cuFile API) is the tier that tries to delete the CPU hop entirely. The structural tell is its base class: where disk was a StorageBackendInterface that borrowed CPU memory, GdsBackend is an AllocatorBackendInterface (gds_backend.py:166) — it owns its own pool, and that pool lives on the GPU. A get allocates from it and the code asserts the result is GPU-resident: assert memory_obj.tensor.is_cuda (:796). So a disk hit materializes in CPU pinned DRAM; a GDS hit materializes directly in GPU VRAM.
For an SSD's DMA engine to write straight into VRAM, that VRAM must first be registered with cuFile (cuFileBufRegister), which pins the GPU pages and exposes their PCIe/BAR1 address as a legal DMA target. The backend registers its whole pool once and records the base in cufile_base_pointer (:335); each read then targets base_pointer + dev_offset (the chunk's slot within the pool). Note this is a different registration from register_kv_caches: that one hands the connector vLLM's scattered paged buffer (the eventual scatter destination); this one registers GDS's own contiguous pool (the SSD read's landing buffer). Two distinct GPU regions, two distinct registrations.
Two paths, and a scatter that's always separate. A crucial point that resolves the obvious "how does it DMA into vLLM's scattered slots?" worry: it doesn't, and it can't. cuFile only does contiguous bulk reads into a registered buffer; it has no notion of slot_mapping. So GDS lands the chunk contiguously in its own GPU pool, and the scatter into vLLM's messy slots is the same multi_layer_kv_transfer kernel from step ⑨ — except, because the source is now GPU-resident, it runs device-to-device instead of host-to-device (the retrieve path explicitly allows GPU-resident MemoryObjs, cache_engine.py:868). The SSD read and the slot-scatter are decoupled steps. _load_gds (:1028) is where the first step forks:
if self.cufile: # true GDS: SSD --DMA--> GDS's GPU pool, zero CPU
with self.cufile.CuFile(path, "r") as f:
return f.read(gpu_pointer, size, file_offset=..., dev_offset=...)
elif self.cudart: # fallback: SSD --mmap--> CPU --cudaMemcpy--> GDS's GPU pool
mm = mmap.mmap(fd, file_size, prot=PROT_READ, flags=MAP_PRIVATE | MAP_POPULATE)
self.cudart.cudaMemcpy(gpu_dst + dev_offset, cpu_src + file_offset, size, H2D)
Counting the actual data moves makes the tiers comparable — and surfaces a non-obvious result:
| path | SSD→CPU | CPU→GPU | GPU→GPU scatter | total moves | CPU touches |
|---|---|---|---|---|---|
| disk | read_file | — (fused into the scatter) | scatter = CPU→slots (H2D) | 2 | 1 |
| GDS, cuFile | — (cuFile DMA SSD→pool) | — | scatter = pool→slots (D2D) | 2 | 0 |
| GDS, fallback | mmap | cudaMemcpy→pool | scatter = pool→slots (D2D) | 3 | 1 |
Two things stand out. First, disk has no cudaMemcpy anywhere — it returns a CPU object and lets retrieve's scatter kernel do the CPU→GPU move fused with the scatter, in one pass. Second, even true GDS still pays the GPU→GPU scatter (its pool ≠ vLLM's slots), so GDS's entire win is narrow and specific: it turns the first hop, SSD→its-pool, into a zero-CPU cuFile DMA. And the fallback is worse than disk: because GdsBackend always insists on filling its own contiguous GPU pool, when cuFile is unavailable it still does mmap+cudaMemcpy into that pool and then scatters out of it — an extra GPU staging buffer and an extra copy that disk simply never has.
The walkthrough on one page
The twelve steps, replayed for the running example:
Phase A, prompt 0 (cache empty)
│
├── ①–② lookup: keys for the 512-token prefix → 0 hits
├── prefill computes all KV into paged blocks
└── ⑪–⑫ wait_for_save: D2H gather → StorageManager → CPU tier
(the trailing partial chunk is dropped, never stored)
Phase A, prompt 1 (same batch!)
│
├── ①–② lookup: same prefix → same chunk keys → 512-token hit, chunks pinned
├── ③ allocate_slots ok → can_load = True
├── ④–⑥ ReqMeta{slot_mapping, LoadSpec, SaveSpec} → pickled → worker
├── ⑦–⑨ start_load_kv → retrieve: tier walk finds CPU has all → H2D scatter into slots
├── ⑩ forward computes only the un-hit tail
└── ⑪–⑫ wait_for_save: unpin; nothing new to store (all chunks already present)
Later, under memory pressure
│
├── CPU pool full → LRU evicts an unpinned chunk → demoted to disk (<key>.pt)
└── next lookup: CPU claims the leading run, disk claims the rest;
retrieve stages the file through the pinned pool → promote-on-read: hot again
vLLM's story was about KV cache inside GPUs; LMCache's begins when a chunk must outlive its GPU block. Three moves carry the whole design: a connector boundary narrow enough to pickle (steps ④–⑥), content-addressed chunks whose chained keys turn lookup into a prefix walk (steps ①–②, ⑧), and a tier stack organized by memory ownership (steps ⑨, ⑫, and the tour). Everything else in the repo is elaboration.
References
- LMCache — the official LMCache repository.
- vLLM — the official vLLM repository.
- Inside vLLM: Anatomy of a High-Throughput LLM Inference System — Aleksa Gordić's companion deep-dive into the vLLM engine.